

Written in London by me
Back to the index
Native Execution on Kubernetes
With Spark 3.1.1, native execution support for Kubernetes has become generally available. The previous article explains how Docker Desktop's K8s bundle can be installed and how a suitable local Kubernetes cluster can be launched. This article will utilise the Kubernetes backend and explore the various ways in which Spark applications can be natively submitted to it. The following diagram illustrates the different deployment options discussed below ((1) to (4)) on a small Kubernetes cluster:
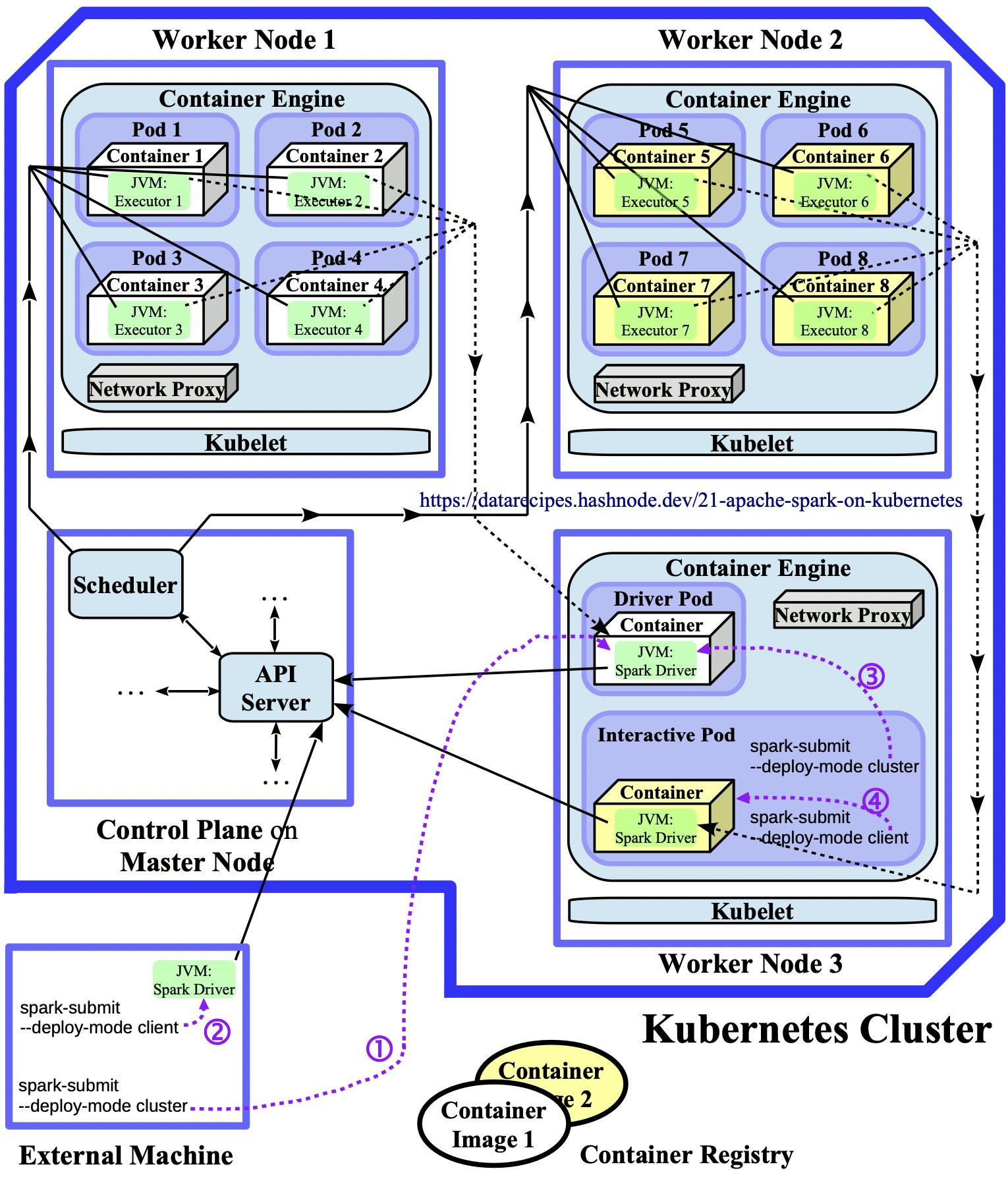 Diagram 2.3: Native Execution Architecture
Diagram 2.3: Native Execution Architecture
For space reasons, most control plane components are not included, they are drawn in the architecture sketch 2.1 from the previous post. The picture above is the "native submission" counterpart to the standalone diagram 2.2. Both visualise a scenario in which eight containerised Spark executors run on a K8s cluster, but important differences exist between these two deployment strategies, for example:
- Each Spark executor runs in a single-container pod. In the standalone approach, a single pod/container often wraps multiple executors.
- Different applications can use different container images.
- There is no intermediate Spark Master in diagram 2.3, applications can therefore directly utilise Kubernetes objects and features like namespaces, service accounts, elasticity, etc.
In the Docker Desktop environment used throughout this article, all rectangles coincide into a single dev machine rectangle and all processes run in (containers inside) Docker containers. Only two executors will be spawned per app submission.
Environment Preparations
One parameter that remains constant across the "external" deployment alternatives below is the Spark master URL string that is passed to the spark-submit commands. The Spark driver connects to the API server whose endpoint is https://kubernetes.docker.internal:6443 on my dev machine according to the messages printed out by kubectl cluster-info:
$ kubectl config use-context docker-desktop
Switched to context "docker-desktop".
$ kubectl cluster-info
Kubernetes control plane is running at https://kubernetes.docker.internal:6443
CoreDNS is running at https://kubernetes.docker.internal:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
The API server is a control plane component so the relevant URL is mentioned at the end of the "Kubernetes control plane is running at" entry. When kubectl points to a real-world K8s cluster, the corresponding line will likely start with "Kubernetes master is running at http...". In the actual spark-submit commands, the endpoint needs to be prefixed by k8s:// which, in my case, results in the master string k8s://https://kubernetes.docker.internal:6443. Omitting the HTTP protocol (i.e., k8s://kubernetes.docker.internal:6443) would also be acceptable since it defaults to https. The localhost address that was printed out by the authenticating proxy in the K8s Dashboard segment can also be used as long as the proxy is running, this would result in the alternative master URL k8s://http://127.0.0.1:8001 given the following info message:
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
Instead of manually retrieving the API server address and copy-pasting it into the --master slot of submit commands each time, a dedicated environment variable can be declared and referenced later on:
$ K8_API_URL=$(kubectl config view --minify -o jsonpath="{.clusters[0].cluster.server}")
$ echo $K8_API_URL
https://kubernetes.docker.internal:6443
The control address might change after cluster restarts in which case the first assignment needs to be repeated. Furthermore, it is advisable to "manually" download certain container images from a registry so the pods can directly pull them from the local cache. When a larger Docker image like bdrecipes/spark-on-docker is pulled for the first time in a Docker Desktop cluster, timeouts during the pod bootstrapping phase can occur if the download process takes several minutes. Therefore, the following command should be entered whenever a new K8s cluster is provisioned and examples from this article are used:
$ docker pull bdrecipes/spark-on-docker:latest
latest: Pulling from bdrecipes/spark-on-docker
[...]
Digest: sha256:e3107d88206f...
Status: Downloaded newer image for bdrecipes/spark-on-docker:latest
docker.io/bdrecipes/spark-on-docker:latest
When Docker Desktop's K8s integration is used, the default service account may already hold sufficient permissions. This K8s construct is explained in more detail in the introduction. The minikube environment is more restrictive in this respect, so a dedicated ServiceAccount is created in the twin article and all app submissions reference this account explicitly. While not strictly necessary, the same approach is followed here. A suitable ServiceAccount named bigdata-sa with sufficient read/write access can be created with the following command pair:
$ kubectl create serviceaccount bigdata-sa
serviceaccount/bigdata-sa created
$ kubectl create rolebinding bigdata-rb --clusterrole=edit --serviceaccount=default:bigdata-sa
rolebinding.rbac.authorization.k8s.io/bigdata-rb created
This ServiceAccount will be used by all Spark pods that are started over the course of this post. For simplicity, all pods will be launched into the default namespace.
Everything is prepared now for launching the first orchestrated Spark app. Initially, only the cluster deploy mode could be used on K8s backends, client mode support was implemented in Spark 2.4. The deploy mode of the Spark driver (cluster versus client) is orthogonal to the launch environment (within cluster vs. outside of cluster) which results in four possible combinations. These are represented as (1) to (4) in the diagram at the top of this page. Jupyter notebooks and the Spark REPL are two popular examples of client mode applications.
Counter-intuitively, additional configuration steps are required when apps are launched from within the cluster. The rest of this article covers all four deployment alternatives and utilises additional Kubernetes constructs where necessary.
Cluster External Application Submissions
One deployment strategy consists in starting the submitting process from the "outside" of the K8s cluster, directly from the dev machine. When using Docker Desktop, the K8s cluster is not truly remote but runs within its sandbox so the launch and cluster environments are identical. The next section describes the external cluster deploy mode, the external client alternative is explored afterwards:
External Cluster Deploy Mode (1)
As described in detail in the Docker article, the pre-built bdrecipes image embeds a Spark distribution alongside all required application artefacts. Therefore, every container that is instantiated from this image will be equipped with Spark libraries and the spark-submit script. However, the submit script does not get called from within a container/pod below so a similar Spark distribution needs to be present in the local launch environment. On my dev machine, spark-3.1.1-bin-hadoop3.2.tgz was unpacked in the home directory, the spark-submit script therefore resides under ~/spark-3.1.1-bin-hadoop3.2/bin/. This results in the following command for running QueryPlansDocker.scala against Kubernetes in cluster mode with two executors:
$ K8_API_URL=$(kubectl config view --minify -o jsonpath="{.clusters[0].cluster.server}")
$ ~/spark-3.1.1-bin-hadoop3.2/bin/spark-submit \
--master k8s://$K8_API_URL \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.driver.pod.name=driver-pod \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--class module1.scala.QueryPlansDocker \
local:///opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
When the pythonic counterpart query_plans_docker.py is executed, no JAR file needs to be specified:
$ K8_API_URL=$(kubectl config view --minify -o jsonpath="{.clusters[0].cluster.server}")
$ ~/spark-3.1.1-bin-hadoop3.2/bin/spark-submit \
--master k8s://$K8_API_URL \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.driver.pod.name=driver-pod \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
local:///opt/spark/work-dir/tutorials/module1/python/query_plans_docker.py \
/opt/spark/work-dir/resources/warc.sample
An important difference to the client deploy mode described later on is that the last two command lines (which specify the JAR/Python source and the input file) reference "container locations". Whenever Spark apps are executed in cluster mode against a K8s backend, both the driver and executors are containerised. Therefore, neither bdrecipes-phil.jar/query_plans_docker.py nor the program input warc.sample needs to be present in the local environment from which the submitting process is started. During the bdrecipes/spark-on-docker image build process (described here), all relevant dependencies were copied to the image filesystem and their target paths are reflected in both submit commands.
Entering one of the commands mentioned above invokes the scheduler backend and log messages inform us immediately whether the application has been launched successfully:
INFO LoggingPodStatusWatcherImpl: State changed, new state:
pod name: driver-pod
namespace: default
labels: spark-app-selector -> spark-c332237667c340a39532c26ba435457f, spark-role -> driver
pod uid: 91f2cf72-7173-4152-820a-ede927bcfac8
service account name: bigdata-sa
volumes: spark-local-dir-1, spark-conf-volume-driver, kube-api-access-dls76
node name: docker-desktop
phase: Running
container status:
container name: spark-kubernetes-driver
container image: bdrecipes/spark-on-docker:latest
container state: running
INFO LoggingPodStatusWatcherImpl: Application status for spark-c332237667c340a39532c26ba435457f (phase: Running)
INFO LoggingPodStatusWatcherImpl: Application status for spark-c332237667c340a39532c26ba435457f (phase: Running)
[...]
The Spark driver will get detached from the launch environment and run in a pod. After a few seconds, two worker pods should be spawned up in which the two requested executor instances are embedded. Entering kubectl get pods multiple times in short succession during this bootstrapping phase will confirm the description. The Dashboard UI which was enabled in the K8s introduction visualises the three Spark pods nicely:
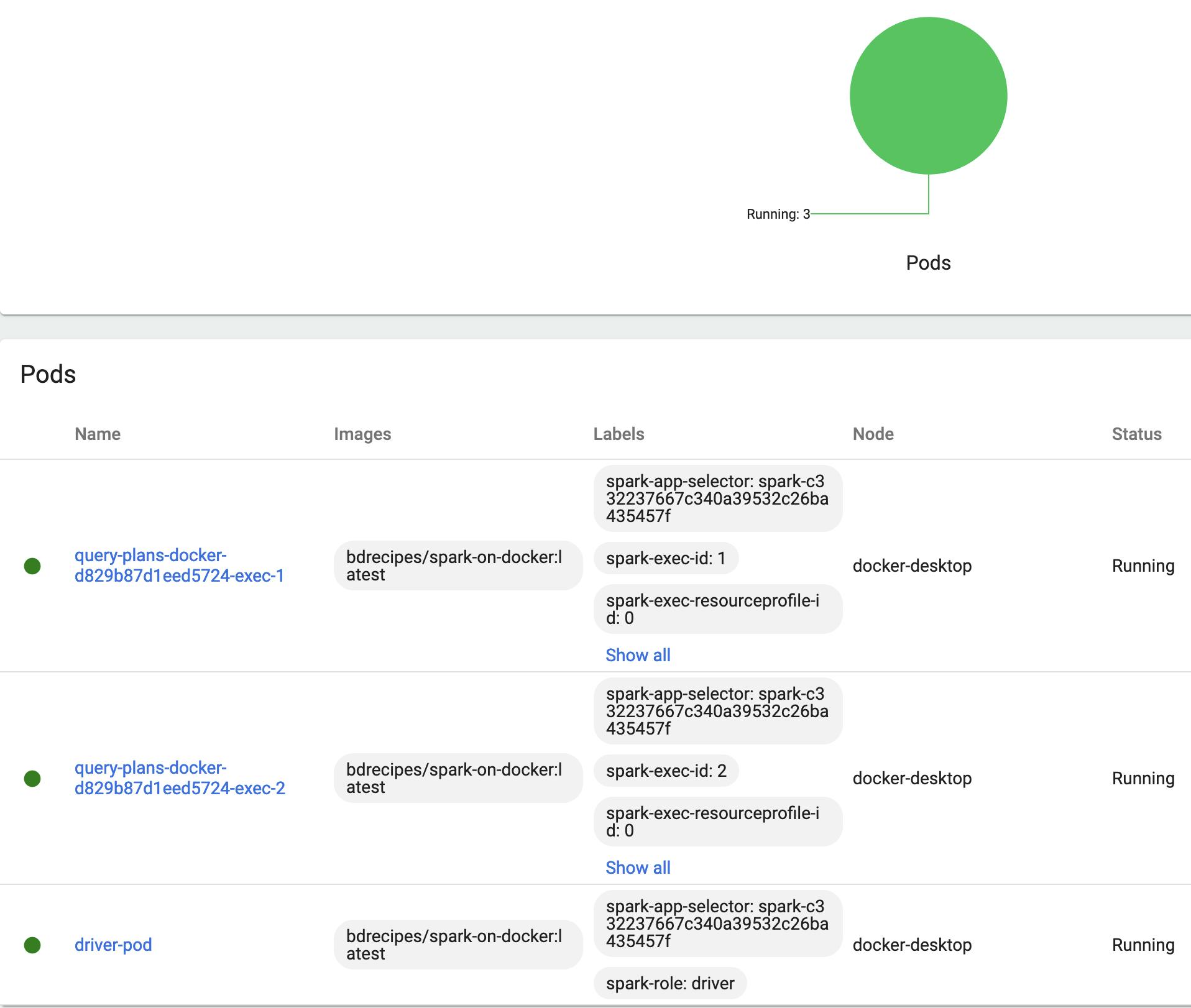
Since the Spark driver detaches, we only get to see major app status updates like phase: Running in the terminal in which the submitting process was invoked. The driver logs provide more fine-grained information. In the Dashboard, they can be viewed by clicking on the Logs action in the rightmost column of the Workloads // Pods tab. Or, more idiomatically, with the kubectl logs command:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
driver-pod 1/1 Running 0 3m44s
query-plans-docker-d829b87d1eed5724-exec-1 1/1 Running 0 3m34s
query-plans-docker-d829b87d1eed5724-exec-2 1/1 Running 0 3m34s
$ kubectl logs driver-pod
[...]
INFO DAGScheduler: Job 5 finished: show at QueryPlansDocker.scala:32, took 1.165123 s
INFO CodeGenerator: Code generated in 18.063 ms
+-----+----------------+---------+
| tag|count(targetURI)| language|
+-----+----------------+---------+
| en| 5| english|
|pt-pt| 1|portugese|
| cs| 1| czech|
| de| 1| german|
| es| 4| spanish|
| eu| 1| basque|
| it| 1| italian|
| hu| 1|hungarian|
|pt-br| 1|portugese|
| fr| 1| french|
|en-US| 6| english|
|zh-TW| 1| chinese|
+-----+----------------+---------+
[...]
The programs QueryPlansDocker.scala/query_plans_docker.py are taken from §10.1 which describes Catalyst’s query plans. After the main logic is executed, the programs are frozen for ten minutes to have enough time for exploring the web UI and query plan visualisations. The Spark UI can be accessed at localhost:4040 after using the kubectl port-forward command with the driver pod name:
$ kubectl port-forward driver-pod 4040:4040
Forwarding from 127.0.0.1:4040 -> 4040
Forwarding from [::1]:4040 -> 4040
The two executor pods will be garbage collected shortly after the app completes successfully which takes around 11 minutes. The driver pod will linger around longer in a Completed state but should not consume memory or CPU cycles. Pods can always be manually removed on the K8s Dashboard with the Delete action to the very right in the Workloads//Pods table or, more idiomatically, with kubectl delete:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
driver-pod 0/1 Completed 0 27m
$ kubectl delete pod driver-pod
pod "driver-pod" deleted
Everything is cleaned up now so the second deploy mode can be explored:
External Client Deploy Mode (2)
A few resource resolution adjustments need to be made before the client mode can be used from the local environment: Most obviously, the value passed to the --deploy-mode option needs to be changed from cluster to client. When this mode is used from the "outside" of the K8s cluster, the driver does not detach into a pod but keeps running in the terminal session from where the submit script is called. Since the warc.sample input file that is consumed by QueryPlansDocker.scala / query_plans_docker.py needs to be scanned by the Spark driver and the executors, a file access problem arises: The executors will still be containerized and the input file is part of their underlying Docker image at /opt/spark/work-dir/resources/warc.sample. However, the driver process will not run inside a pod so the contents of the bdrecipes/spark-on-docker image are out of scope. The easiest solution to this access problem consists in creating a new directory /opt/spark/work-dir/resources/ locally and placing an uncompressed copy of warc.sample into it. Alternatively, the creation of a link with the name /opt/spark/work-dir/resources/warc.sample would also work:
$ ln /Users/me/IdeaProjects/bdrecipes/resources/warc.sample /opt/spark/work-dir/resources/warc.sample
The input file is located at /Users/me/IdeaProjects/bdrecipes/resources/warc.sample on my dev machine and the previous command has created a hard link to it.
Providing the program sources is easier since they are not needed by the Spark executors, only the driver process has to access them: After compiling the KubernetesImage branch of the bdrecipes project with mvn clean install (see §0.1), the assembled JAR file can be found at ~/IdeaProjects/bdrecipes/target/bdrecipes-phil.jar on my system. The Python source file query_plans_docker.py is located at ~/IdeaProjects/bdrecipes/tutorials/module1/python/query_plans_docker.py. With the following command pair, the programs can be executed from a local launch environment in client mode:
Executing QueryPlansDocker.scala in client mode:
$ K8_API_URL=$(kubectl config view --minify -o jsonpath="{.clusters[0].cluster.server}")
$ ~/spark-3.1.1-bin-hadoop3.2/bin/spark-submit \
--master k8s://$K8_API_URL \
--deploy-mode client \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--conf spark.executor.instances=2 \
--class module1.scala.QueryPlansDocker \
~/IdeaProjects/bdrecipes/target/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
Executing query_plans_docker.py in client mode:
$ K8_API_URL=$(kubectl config view --minify -o jsonpath="{.clusters[0].cluster.server}")
$ ~/spark-3.1.1-bin-hadoop3.2/bin/spark-submit \
--master k8s://$K8_API_URL \
--deploy-mode client \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--conf spark.executor.instances=2 \
~/IdeaProjects/bdrecipes/tutorials/module1/python/query_plans_docker.py \
/opt/spark/work-dir/resources/warc.sample
Only two pods are bootstrapped after the app submission, one less compared to the cluster deploy mode covered above. The Spark driver does not detach from the local terminal session, so a driver pod is not needed. Furthermore, the driver logs are printed directly to the terminal which is similar to a non-distributed execution scenario with --master local[*].
Cluster Internal Application Submissions
In the preceding examples, the spark-submit command was called from the "outside" of the K8s cluster. The program launch can also be initiated from within the cluster, via an intermediary interactive/bastion pod for example. Such interactive containers can be spawned with the interactive_pod.yaml specification:
$ kubectl apply -f https://raw.githubusercontent.com/g1thubhub/bdrecipes/KubernetesImage/scripts/interactive_pod.yaml
pod/interactive-pod created
$ kubectl exec -it interactive-pod -- sh
sh-5.0$
After submitting the K8s resource with the first command, we enter the interactive pod's shell with kubectl exec so a new prompt sh-5.0$ appears. This interactive shell can now be used for scheduling workloads:
Interactive Pod - Cluster Mode (3)
The program execution from pods is similar to the multi-container app scenario described in the Docker article: The underlying bdrecipes/spark-on-docker image contains all necessary artefacts, so no issues will arise when commands only reference container-internal files. Furthermore, the submit script itself is also present in the Docker container (at /opt/spark/bin/spark-submit) so everything will run from instances of the image. This results in the following "self-sufficient" configuration for executing QueryPlansDocker.scala from an interactive pod in cluster mode:
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode cluster \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.driver.pod.name=driver-pod \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--class module1.scala.QueryPlansDocker \
local:///opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
Only two arguments need to be modified for running query_plans_docker.py:
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode cluster \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.driver.pod.name=driver-pod \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
local:///opt/spark/work-dir/tutorials/module1/python/query_plans_docker.py \
/opt/spark/work-dir/resources/warc.sample
Two authentication properties are specified, their values are supplied by the environment variables CACERT and TOKEN which are declared in the interactive_pod.yaml manifest. The security/networking part from the last article explains why these additional props are necessary.
In total, four pods are now involved: Because of the cluster deploy mode, the driver detaches from the interactive pod and runs within a dedicated driver pod. As in all the other deployment scenarios, the actual computational work is performed by two executors pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
driver-pod 1/1 Running 0 44s
interactive-pod 1/1 Running 0 11m
query-plans-docker-54d13a7cbcd31b42-exec-1 1/1 Running 0 37s
query-plans-docker-54d13a7cbcd31b42-exec-2 1/1 Running 0 37s
Interactive Pod - Client Mode (4)
The most involved deployment scenario described in this post is the "client mode via interactive pod" combination. The script parameters from the last section can be reused, only the cluster argument needs to be substituted with client. This results in the following configuration for executing QueryPlansDocker.scala in client mode from an interactive pod:
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode client \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--class module1.scala.QueryPlansDocker \
local:///opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
Its pythonic counterpart for query_plans_docker.py is:
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode client \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
local:///opt/spark/work-dir/tutorials/module1/python/query_plans_docker.py \
/opt/spark/work-dir/resources/warc.sample
After entering these commands, the driver process starts in the interactive pod and requests two executor pods. However, the application does not seem to progress and is stuck in an infinite loop:
$ kubectl apply -f https://raw.githubusercontent.com/g1thubhub/bdrecipes/KubernetesImage/scripts/interactive_pod.yaml
pod/interactive-pod created
$ kubectl exec -it interactive-pod -- sh
# # # # # # # # # # # # # # # # # # # # # # # #
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode client \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--class module1.scala.QueryPlansDocker \
local:///opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
INFO SparkContext: Running Spark version 3.1.1
INFO ResourceUtils: ==============================================================
INFO ResourceUtils: No custom resources configured for spark.driver.
INFO ResourceUtils: ==============================================================
INFO SparkContext: Submitted application: Query Plans Docker
[...]
INFO Utils: Successfully started service 'sparkDriver' on port 43747.
[...]
WARN Initial job has not accepted any resources; check cluster UI to ensure that workers are registered and have sufficient resources
INFO Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2 running: 1.
INFO Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2 running: 1.
WARN Initial job has not accepted any resources; check cluster UI to ensure that workers are registered and have sufficient resources
INFO Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2 running: 1.
INFO Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2 running: 1.
WARN Initial job has not accepted any resources; check cluster UI to ensure that workers are registered and have sufficient resources
[...]
The architectures of Spark and Kubernetes are responsible for this unsuccessful attempt: According to the official documentation,
The driver program must listen for and accept incoming connections from its executors throughout its lifetime [...]. As such, the driver program must be network addressable from the worker nodes.
So far, there was no necessity to modify networking aspects, everything has worked fine after injecting the correct script parameters. But this is about to change: Pods can directly contact the API server but additional configuration steps are often required for opening direct pod-to-pod communication paths. These are drawn as dotted black lines in the diagram at the top of this post. The official suggestion is to create a headless service with the kubectl expose command, service objects like these are discussed in more detail in the preceding article.
Before a headless service can be created, the interactive pod must be up and running, the command used at the beginning of this section is kubectl apply -f https://raw.githubusercontent.com/g1thubhub/bdrecipes/KubernetesImage/scripts/interactive_pod.yaml. Entering kubectl expose pod interactive-pod --type=ClusterIP --cluster-ip=None in a new local terminal window will create a suitable service that makes the driver/interactive pod accessible for the executor pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
interactive-pod 1/1 Running 0 4m50s
$ kubectl expose pod interactive-pod --type=ClusterIP --cluster-ip=None
service/interactive-pod exposed
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
interactive-pod ClusterIP None <none> <none> 38s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28h
The unsuccessful spark-submit commands can now be repeated and the insufficient resource loops should not occur. As before, the following command executes QueryPlansDocker.scala from an interactive pod in client mode:
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode client \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
--class module1.scala.QueryPlansDocker \
local:///opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
The pythonic counterpart for query_plans_docker.py is:
# From the interactive pod's terminal:
sh-5.0$ /opt/spark/bin/spark-submit \
--master k8s://https://kubernetes.default:443 \
--deploy-mode client \
--conf spark.kubernetes.authenticate.submission.caCertFile=$CACERT \
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=$TOKEN \
--conf spark.kubernetes.container.image=bdrecipes/spark-on-docker:latest \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=bigdata-sa \
local:///opt/spark/work-dir/tutorials/module1/python/query_plans_docker.py \
/opt/spark/work-dir/resources/warc.sample
The messages
INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) with ID 1, ResourceProfileId 0
INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) with ID 2, ResourceProfileId 0
should now appear near the beginning of the logging output in the interactive shell and the application should succeed.
After all experiments have concluded, the headless service should be removed:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
interactive-pod ClusterIP None <none> <none> 38s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28h
$ kubectl delete service interactive-pod
service "interactive-pod" deleted
We have mastered various deployment options for Spark on K8s in a learning environment and are now well prepared for the transition to a cluster that is hosted on a cloud platform. But that is the topic of another article.